
一、准备工作
1.服务器信息
| 序号 | hostname | ip | 配置 | 主要进程 |
|---|---|---|---|---|
| 1 | hanode01 | 192.168.0.201 | 4核8g1T | NameNode,ZKFC,HMaster,Keepalived |
| 2 | hanode02 | 192.168.0.202 | 4核8g1T | NameNode,ZKFC,HMaster,Keepalived |
| 3 | hanode03 | 192.168.0.203 | 4核8g1T | ResourceManager |
| 4 | hanode04 | 192.168.0.204 | 4核8g1T | ResourceManager |
| 5 | hanode05 | 192.168.0.205 | 4核8g1T | DataNode,NodeManager,JournalNode,QuorumPeerMain,HRegionServer |
| 6 | hanode06 | 192.168.0.206 | 4核8g1T | DataNode,NodeManager,JournalNode,QuorumPeerMain,HRegionServer |
| 7 | hanode07 | 192.168.0.207 | 4核8g1T | DataNode,NodeManager,JournalNode,QuorumPeerMain,HRegionServer |
2.软件版本
| 软件 | 版本 |
|---|---|
| java | 1.8.x |
| zookeeper | 3.6.2 |
| hadoop | 3.2.1 |
3.搭建用户
root
4.创建文件目录
# 在7台服务器上执行
$ mkdir -pv /hdata/hadoop_data/{datanode,namenode.temDir}5. 配置hosts解析
# 所有服务器配置
$ sudo vim /etc/hosts
192.168.0.201 hanode01
192.168.0.202 hanode02
192.168.0.203 hanode03
192.168.0.204 hanode04
192.168.0.205 hanode05
192.168.0.206 hanode06
192.168.0.207 hanode076.配置免密登陆
- 只在hanode01,02,03,04上配置
$ ssh-keygen #分别在01,02,03及04上执行
# 分发到所有主机
$ scp-copyid hanode01 # 分别在01,02,03及04上执行,并分发到hanode01~07二、部署
1.jdk部署
- 准备好java安装包,放置到/opt/software/src下,以hanode01为中心分发到hanode01-hanode07服务器上,以脚本的方式安装。
a> 脚本内容
$ vim /opt/software/src/jdk_install.sh #!/bin/bash # 拷贝文件 ## color变量 # 脚本执行过程失败,自动退出 set -e green="\e[1;32m" color="\e[0m" red="\e[1;31m" # 此脚本基于ssh秘密登陆 IP=' hanode01 hanode02 hanode03 hanode04 hanode05 hanode06 hanode07 ' # 创建jdk安装路径 for node in ${IP};do ssh root@${node} 'echo hadoop | sudo -S mkdir -p /usr/java && sudo -S chown root:root /usr/java' # 拷贝文件 scp -r /opt/software/src/jdk1.8.0_151.tar.gz ${node}:/usr/java ssh root@${node} '/bin/tar xf /usr/java/jdk1.8.0_151.tar.gz -C /usr/java && rm /usr/java/jdk1.8.0_151.tar.gz' if [ $? -eq 0 ];then echo -e "$green ${node} 文件copy完成 $color" else echo -e "$red ${node} 文件copy失败 $color" fi # 配置jdk环境变量 ssh root@${node} 'echo -e "#java\nexport JAVA_HOME=/usr/java/jdk1.8.0_151\nexport PATH=$JAVA_HOME/bin:$PATH\nexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar">/etc/profile.d/java.sh && source /etc/profile.d/java.sh' if [ $? -eq 0 ];then echo -e "$green ${node} 安装完成 $color" else echo -e "$red ${node} 安装失败 $color" fi doneb> 执行脚本
$ pwd /opt/software/src $ ls java_install.sh jdk1.8.0_151.tar.gz $ bash java_install.sh # 安装完成关闭所有终端,重新启xshell连接或直接输入bash,生成新的连接终端
2.zookeeper配置
在hanode05,06或07任意一台服务器操作
2.1 zookeeper安装
a> 解压apache-zookeeper-3.6.2-bin.tar.gz 到/opt/software目录下
$ pwd /opt/software $ tar -xvf apache-zookeeper-3.6.2-bin.tar.gz -C /opt/softwareb> 编辑/etc/profile,配置zookeeper环境变量
$ echo -e "#zk\nexport ZOOKEEPER_HOME=/opt/software/\nexport PATH=\$PATH:\$ZOOKEEPER_HOME/bin" >> /etc/profile.d/zookeeper.shc> 执行source命令,使环境变量生效
$ source /etc/profile.d/zookeeper.shd> 创建数据存储目录和日志存储目录
$ mkdir -pv cd /opt/software/apache-zookeeper-3.6.2-bin/{data,log}e> 修改zookeeper配置
$ cd /opt/software/apache-zookeeper-3.6.2-bin/conf $ cp zoo_sample.cfg zoo.cfg $ vim zoo.cfg # The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/opt/software/apache-zookeeper-3.6.2-bin/data dataLogDir=/opt/software/apache-zookeeper-3.6.2-bin/log # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 ## Metrics Providers # # https://prometheus.io Metrics Exporter #metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider #metricsProvider.httpPort=7000 #metricsProvider.exportJvmInfo=true server.0=hanode05:3888:4888 server.1=hanode06:3888:4888 server.2=hanode07:3888:4888- 完成配置如图
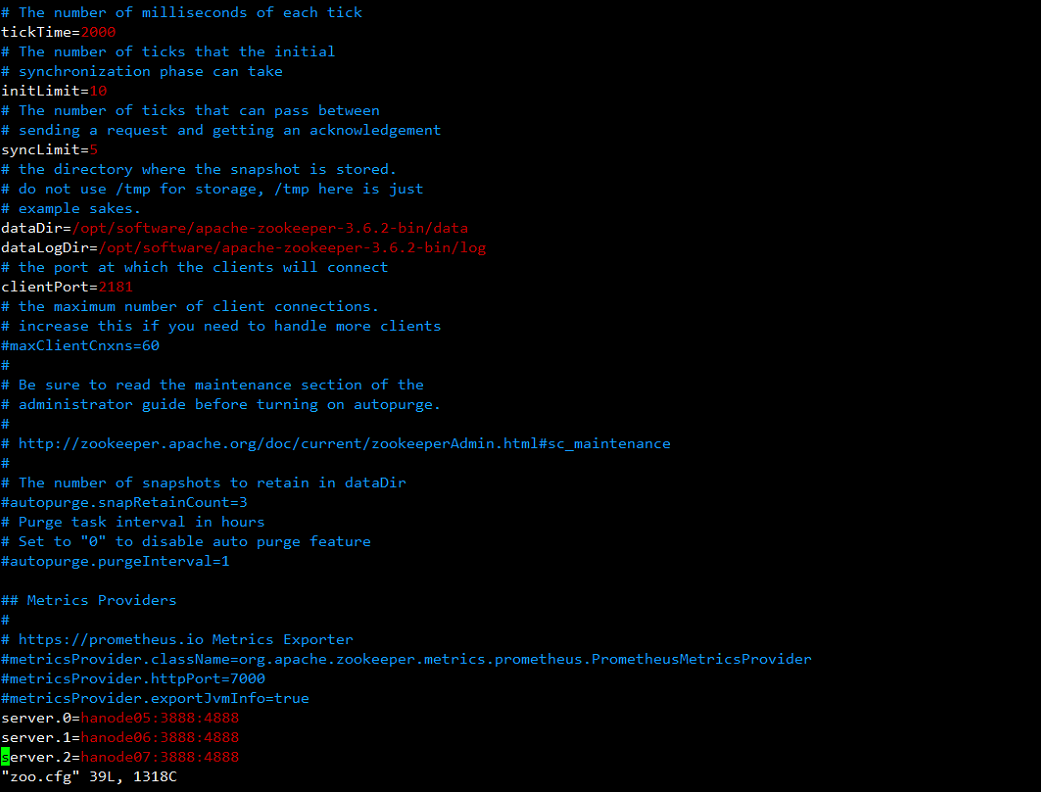
f> 在dataDir创建myid文件,myid文件中写入zoo.conf配置的id编号,注意每台服务器写入的内容要与配置文件zoo.conf中配置的server.id保持一致,这是服务器之间唯一不同的地方。要分别修改。
$ echo 0 > /opt/software/apache-zookeeper-3.6.2-bin/data/myidg> 将配置完成的zookeeper完整目录复制到其他的服务器节点/opt/software目录下,修改环境变量,修改myid文件。
$ scp -r /opt/software/apache-zookeeper-3.6.2-bin node06:/opt/software $ scp -r /opt/software/apache-zookeeper-3.6.2-bin node07:/opt/software
h> 在每台服务器上分别启动zookeeper
$ zkServer.sh starti> 检查zookeeper状态
$ zkServer.sh status

- 至此,zookeeper集群搭建完成。
2.2、zookeeper安全认证
a> 登陆zookeeper,任意一个节点
$ zkCli.sh -server 192.168.0.205:2181b> 查看当前权限
getAcl /c> 添加可访问ip,视情况而定,
setAcl / ip:192.168.0.205:cdrwa,ip:192.168.0.206:cdrwa,ip:192.168.0.207:cdrwa,ip:192.168.0.204:cdrwa,ip:192.168.0.203:cdrwa,ip:192.168.0.202:cdrwa,ip:192.168.0.201:cdrwad> 查看是否正常添加
getAcl /e> 恢复所有ip可访问
setAcl / world:anyone:cdrwa
3.Hadoop搭建HA机制
在hanode01执行安装
3.1 hadoop安装
a> 解压hadoop-3.2.1.tar.gz 到 /opt/software目录下
$ tar -xvf hadoop-3.2.1.tar.gz -C /opt/softwareb> 增加hadoop环境变量
$ vim /etc/profile.d/hadoop.sh #!/bin/bash #hadoop export HADOOP_PREFIX=/opt/software/hadoop-3.2.1 export HADOOP_HOME=/opt/software/hadoop-3.2.1 export HADOOP_HDFS_HOME=/opt/software/hadoop-3.2.1 export HADOOP_CONF_DIR=/opt/software/hadoop-3.2.1/etc/hadoop export HADOOP_COMMON_LIB_NATIVE_DIR=/opt/software/hadoop-3.2.1/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR" export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATHc> 修改hadoop-env.sh
$ cd /opt/software/hadoop-3.2.1/etc/hadoop $ vim hadoop-env.sh # 增加以下内容,hadoop的操作用户为当前系统账户 export JAVA_HOME=/usr/java/jdk1.8.0_151 export HDFS_NAMENODE_USER="root" export HDFS_DATANODE_USER="root" export HDFS_SECONDARYNAMENODE_USER="root" export YARN_RESOURCEMANAGER_USER="root" export YARN_NODEMANAGER_USER="root"

d> 编辑core-site,xml,此处设置了nameservice的名称及hadoop临时目录和客户端访问zookeeper的地址
$ vim core-site.xml <configuration> <!-- 指定hdfs的nameservice为ns1 --> <property> <name>fs.defaultFS</name> <value>hdfs://ns1/</value> </property> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property> <!-- 指定hadoop临时目录 --> <property> <name>hadoop.tmp.dir</name> <value>/hdata/hadoop_data/temDir</value> </property> <!-- 指定客户端访问zookeeper的地址 --> <property> <name>ha.zookeeper.quorum</name> <value>hanode05:2181,hanode06:2181,hanode07:2181</value> </property> <property> <name>fs.hdfs.impl</name> <value>org.apache.hadoop.hdfs.DistributedFileSystem</value> <description>The FileSystem for hdfs: uris.</description> </property> </configuration>

e> 编辑hdfs-site.xml
$ vim hdfs-site.xml <configuration> <!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致--> <property> <name>dfs.nameservices</name> <value>ns1</value> </property> <!-- ns1下面有两个NameNode,分别是nn1,nn2 --> <property> <name>dfs.ha.namenodes.ns1</name> <value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>hanode01:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.ns1.nn1</name> <value>hanode01:50070</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.ns1.nn2</name> <value>hanode02:9000</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.ns1.nn2</name> <value>hanode02:50070</value> </property> <!-- 指定NameNode的元数据在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hanode05:8485;hanode06:8485;hanode07:8485/ns1</value> </property> <!--指定JournalNode在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/hdata/hadoop_data/journaldata</value> </property> <!-- 开启NameNode失败自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式 --> <property> <name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行--> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence shell(/bin/true) </value> </property> <!-- 使用sshfence隔离机制时需要ssh免登陆--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <!--配置sshfence隔离机制超时时间 --> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> <!--数据副本数--> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/hdata/hadoop_data/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/hdata/hadoop_data/datanode</value> </property> </configuration>


f> 编辑mapred-site.xml
$ vim mapred-site.xml <configuration> <!--指定mr框架yarn方式--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> --> </configuration>

g> 编辑yarn-site.xml
$ vim yarn-site.xml <configuration> <!-- 开启RM高可用 --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- 指定RM的cluster id --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yrc</value> </property> <!-- 指定RM的名字 --> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!-- 分别指定RM的地址 --> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hanode03</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hanode04</value> </property> <!-- 指定zk集群地址 --> <property> <name>yarn.resourcemanager.zk-address</name> <value>hanode05:2181,hanode06:2181,hanode7:2181</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>49152</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>49152</value> </property> </configuration>


h> 编辑workers,配置数据源地址datanode
$ vim workers hanode05 hanode06 hanode07i> 将hadoop3.2.1复制到其他节点/opt/software目录下,并创建数据目录
# 通过脚本分发到hanode02,hanode03,hanode04,hanode05,hanode06,hanode07上 # 脚本内容 $ pwd /opt/software/src/scp_hadoop.sh #!/bin/bash # Author: DT # 颜色 green="\e[1;32m" color="\e[0m" set -e # root账户密码 passwd="root" # 本机创建数据目录 echo -e "$green ${i} 创建hanode01的数据存储目录 $color" mkdir -pv /hdata/hadoop_data/{namenode,datanode,temDir,journaldata} # 定义主机地址 IP=" hanode02 hanode03 hanode04 hanode05 hanode06 hanode07 " for i in $IP;do ssh hadoop@$i 'mkdir -pv /hdata/hadoop_data/{namenode,datanode,temDir,journaldata}' scp -r /opt/software/hadoop-3.2.1 hadoop@$i:/opt/software # scp -r /etc/profile.d/hadoop.sh hadoop@$i:/etc/profile.d sshpass -p $passwd scp -P 22 /etc/profile.d/hadoop.sh root@$i:/etc/profile.d ssh hadoop@$i 'source /etc/profile.d/hadoop.sh' echo -e "$green ${i} 分发完成 $color" donej> 执行分发脚本
$ pwd /opt/software/src $ bash scp_hadoop.shk> 分别在hanode01-07服务器上source环境变量
$ source /etc/profile.d/hadoop.sh
3.2 首次启动
<u>严格按照以下顺序启动HA</u>
a> 检查zookeeper
# 检查hadoop所对应的zookeeper是否启动,hanode05,hanode06,hanode07 $ zkServer.sh statusb> 启动journalnode
# 分别在hanode05,hanode06,hanode07上执行 $ cd /opt/software/hadoop-3.2.1/sbin $ ./hadoop-daemon.sh start journalnode # 检查journalnode进程是否启动 $ jps 1539 JournalNode

c> 开始格式化
# 格式化hdfs,在hanode01上 $ hdfs namenode -format # 在格式化节点hanode01后,开启namenode,在hanode01 $ hdfs --daemon start namenoded> 开启namenode
# hanode02上同步格式化信息 $ hdfs namenode -bootstrapStandby # 在hanode02上同步格式化信后,开启namenode,在hanode02 $ hdfs --daemon start namenodee> 格式化ZKFC(在hanode01上执行即可)
# 交互式时,输入y $ hdfs zkfc -formatZKf> 启动HDFS,在hanode01上
$ cd /opt/software/hadoop-3.2.1/sbin $ ./start-dfs.shg> 启动YARN在hanode03上执行
- 注意:是在ha3上执行start-yarn.sh,把namenode和resourcemanager分开是因为性能问题,因为他们都要占用大量资源,所以把他们分开了,他们分开了就要分别在不同的机器上启动。
# 在hanode03上启动resourcemanager $ cd /opt/software/hadoop-3.2.1/sbin $ ./start-yarn.sh # 此命令只能启动hanode03上的resourceManager 而hanode04上的resourceManager需要手动启动一下 $ ./yarn-daemon.sh start resourcemanagerh> 部署完成
# 此次,hadoop集群HA机制部署完成i> web查看
hanode01
# hadoop01优先启动所以为主 http://192.168.0.201:50070

hanode02
# hanode02为备主节点 http://192.168.0.202:50070

3.3 hadoop非首次启动
a> 启动zookeeper
# 恢复zookeeper,hanode05,hanode06,hanode07 $ zkServer.sh startb> 启动HDFS在hanode01上
$ pwd /opt/software/hadoop-3.2.1/sbin $ start-dfs.shc> 启动YARN在ha3上执行;ha4上的resourceManager需要手动启动
# 在hanode03上启动resourcemanager $ cd /opt/software/hadoop-3.2.1/sbin $ ./start-yarn.sh # 此命令只能启动hanode03上的resourceManager 而hanode04上的resourceManager需要手动启动一下 $ ./yarn-daemon.sh start resourcemanagerd> 启动hanode02的namenode
#手动启动那个挂掉的NameNode $ sbin/hadoop-daemon.sh start namenode
3.4 测试集群工作状态的一些指令:
指令
# 获取当前namenode节点状态 $ hdfs haadmin -getServiceState nn1 WARNING: HADOOP_PREFIX has been replaced by HADOOP_HOME. Using value of HADOOP_PREFIX. active # 单独启动一个namenode进程 $ sbin/hadoop-daemon.sh startnamenode